
This approach is known as kernel density estimation or the Parzen window technique. クラスタリングについては階層的クラスタリングと k-means クラスタリングをやりました今回は混合ガウスモデル Gaussian Mixture Model GMM というクラスタリングの手法ですGMM を使うことでデータ.

K Means Clustering What It Is And How It Works Learn By Marketing

K Means法を解説して実装してみる

Orange Data Mining Interactive K Means
Once we have computed from equation above we can find its local maxima using gradient ascent or some other optimization technique.
K 平均 アルゴリズム. A3l2g1o6 圧縮encodeする際は Run Length Encoding 復元decodeする際は Run Length Decoding と. 平均値などの逐次計算アルゴリズム 20190518 20191012 実験室 アルゴリズム 信号処理 データの平均値をとることは多いですがデータが逐次的に入ってくるときは普通の計算では今までの全てデータが必要で総和を取る必要がありこれは計算量が多いです. K-1ケイ-ワンは空手団体正道会館の石井和義が1993年に創設した打撃系格闘技イベント 基本的にはキックボクシングで ヘビー級を中心とし世界的に知名度が高い 2012年 1月より香港に登記されるK-1 Global Holdings Limitedが商標権等諸権利を取得し世界各地でイベント運営が行なわ.
セグメント木とは セグメント木とは完全二分木全ての葉の深さが等しい木によって実装された区間を扱うのに適したデータ構造のことです 区間に対する操作を対数時間 Olog n で行えることが特徴で競技プログラミングなどで頻出となっています. Is the only parameter in the algorithm and is called the bandwidth. Web教材一覧 アルゴリズム BOK大区分1 基礎理論中区分2 アルゴリズムとプログラミング中区分2 アルゴリズム ソートの種類 学習のポイント.
The MiniBatchKMeans is a variant of the KMeans algorithm which uses mini-batches to reduce the computation time while still attempting to optimise the same objective function. K-means アルゴリズム は経験則を使用して k-means クラスタリングの重心シードを検出します Arthur および Vassilvitskii 1 によるとk-means はロイドのアルゴリズムの実行時間および最終的な解の質を改善します. K近傍法k-nearest neighbor k-NNとk平均法k-means clusteringというのは名前も似てて最初は同じものだと誤解する人もいるでしょう現に私もそう思っていました実際には似たようなアルゴリズムの考え方ですが若干その考え方が違います.
基于K-means聚类算法的图像分割 算法的基本原理 基于K-means聚类算法的图像分割以图像中的像素为数据点按照指定的簇数进行聚类然后将每个像素点以其对应的聚类中心替代重构该图像算法步骤 ①随机选取K个初始聚类中心 ②计算每个样本到各聚类中心的距离同时将每个样本归. Windows にはラウドネス等化という機能がついており 1 これを使うことでシステムの音量を平均化することができます 1 使用しているサウンドデバイスやサウンドドライバーによってはこの機能がないこともある模様 使用中のパソコンにラウドネス等化機能がない場合. 平均計算時間がOn 2 で安定ソートです 比較回数は nn-12 です 交換回数は 約n 2 2 ですしかし並び順によって異なる このアルゴリズムの派生としてシェーカーソートやコムソートが有ります.
データ分析のレシピk-meansのアルゴリズム - いくつかのデータを 指定した数のクラスタにグループ分けする. ランレングス圧縮ランレングス符号化とはデータの圧縮方法の一つで圧縮前に正確に復元することができる可逆圧縮の一種です 同じ文字が連続して何文字出現するかに変換します 例 In. K-means clustering is a method of vector quantization originally from signal processing that aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean cluster centers or cluster centroid serving as a prototype of the clusterThis results in a partitioning of the data space into Voronoi cells.
この記事では 機械学習入門クラスタリングの解説とPythonによるk-means実装 といった内容について誰でも理解できるように解説しますこの記事を読めばあなたの悩みが解決するだけじゃなく新たな気付きも発見できることでしょうお悩みの方はぜひご一読ください. 割り振ったデータをもとに各クラスタの中心 を計算する 計算は通常割り当てられたデータの各要素の. These mini-batches drastically reduce the amount of computation required to converge to a local.
K-平均法は一般には以下のような流れで実装される データの数を クラスタの数を としておく. またk平均法はk-means法とも呼ばれています 機械学習に使用されるアルゴリズム6k近傍法 k近傍法はデータ間の距離を利用して分類を行ったり異常検知を行うアルゴリズムです. Where are the input samples and is the kernel function or Parzen window.
Mini-batches are subsets of the input data randomly sampled in each training iteration. 20151127 アルゴリズムから学ぶAzureMLモジュールの使いこなし方 クラスタリング k-means 機械学習 関連動画. The problem with this brute.
平均時間計算量同じ入力サイズ Onの問題例に対し それらの時間計算量の平均を求める これ以外の方法もある 時間計算量のオーダーが多項式log n n2 n5 理論的には速いアルゴリズム. 前回アルゴリズムの例としてトランプを並べ替える複数の方法を考えました 同じように今回もトランプを例に使います トランプには4つのスートマークがありますが問題を簡単にするためにハートのエースAキングKの13枚を使うことにしましょう.

K平均法とは 機械学習アルゴリズム10種 6 日経クロストレンド
Understanding K Means Clustering In Machine Learning By Dr Michael J Garbade Towards Data Science

クラスター分析の手法 非階層クラスター分析 データ分析基礎知識

K Means Clustering In Python A Practical Guide Real Python
2
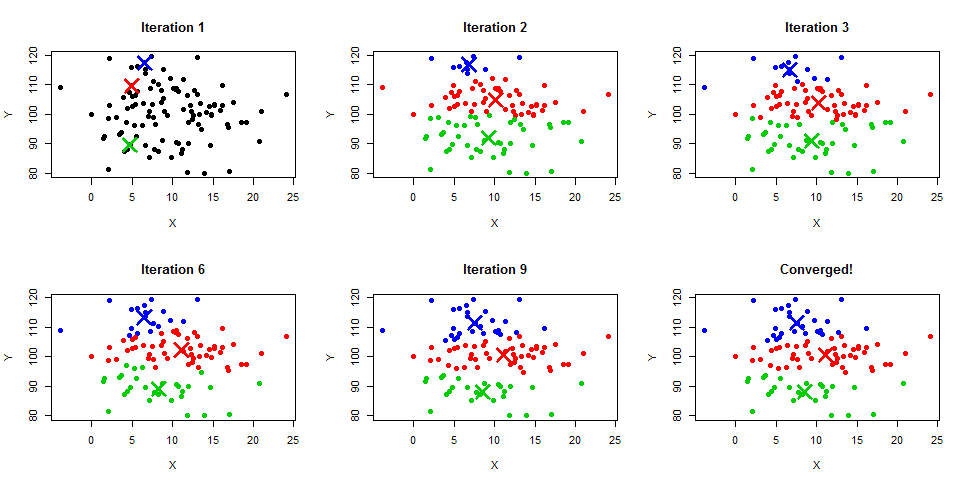
K Means Clustering What It Is And How It Works Learn By Marketing
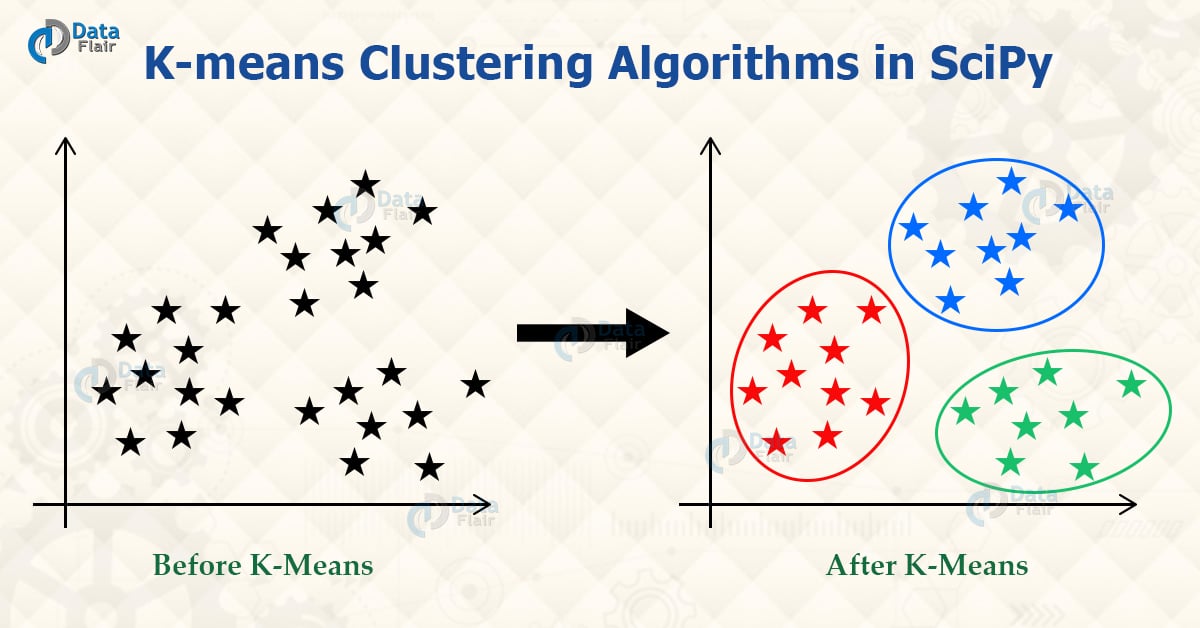
Scipy Cluster K Means Clustering And Hierarchical Clustering Dataflair

K Means Clustering Made Simple Oxford Protein Informatics Group





